Architecture
Sliderule Architecture Overview
Overview
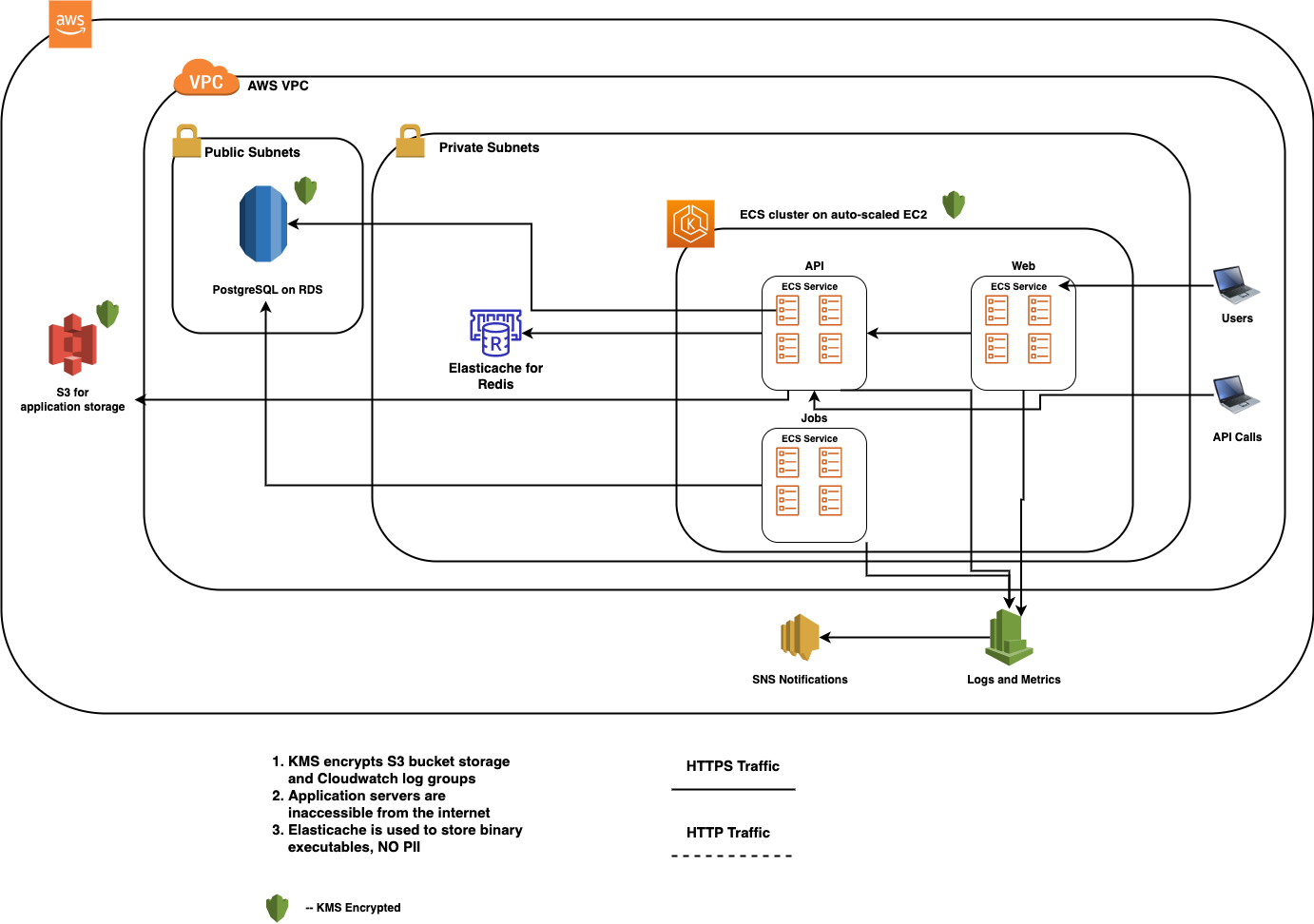
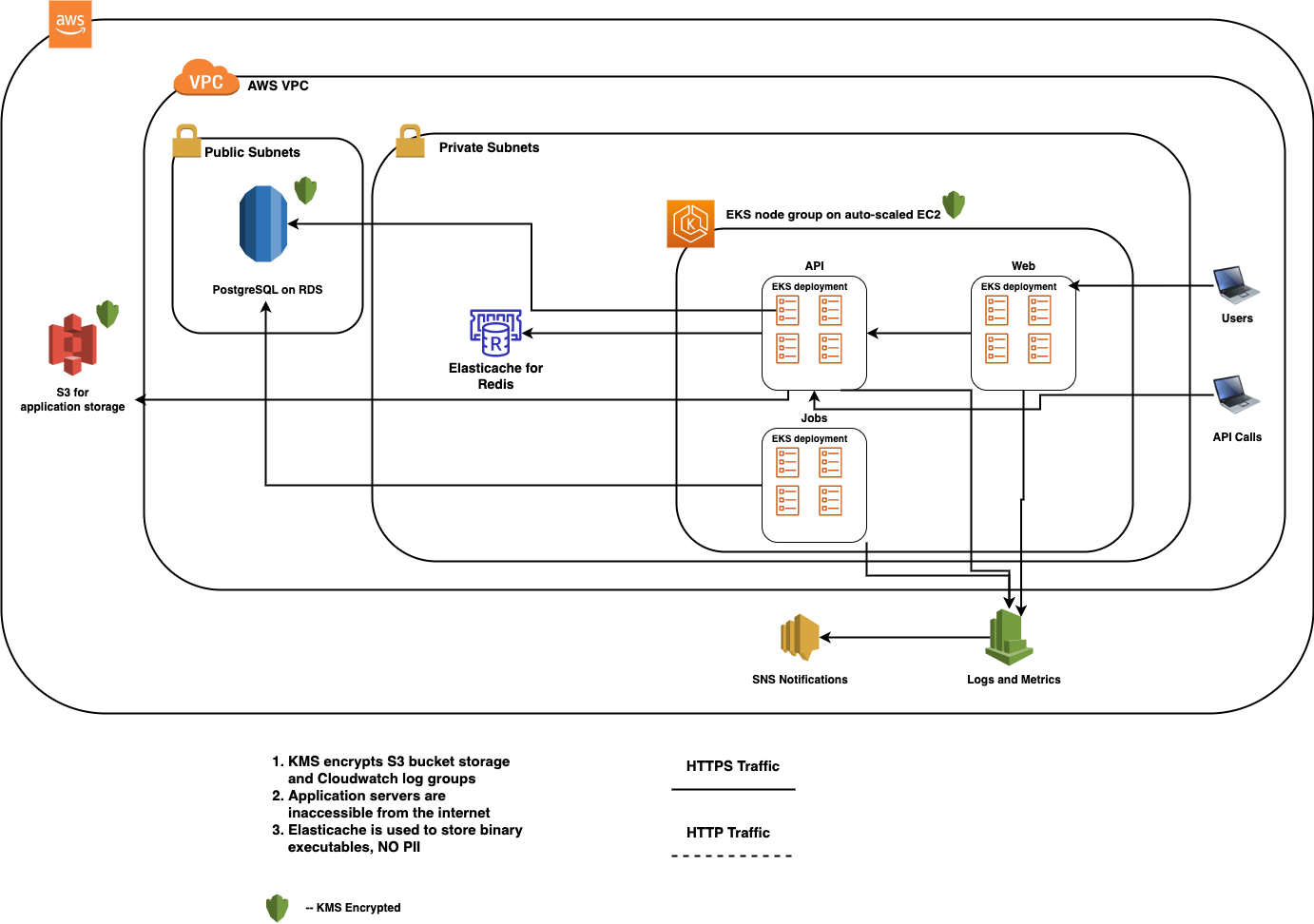
In order to support the performance and scale that Sliderule boasts, it is necessary to draw on an array of supporting technologies. At a high the generic infrastructures Sliderule relies on are:
- Relational Database (Postgres api is preffered): Sliderule uses a relational DB as its primary data store
- Read Replica (sometimes multiple) of Database: Sliderule classifies its functionalities as either primary or secondary. When possible, we put a strong partition between the resources supporting these functionalities, making it impossible for secondary functionality to interfere with the primary. Read replicas is a big way we achieve this.
- In Memory Cache: Sliderule uses this to avoid database calls (which are relatively costly and bottlenecked) during workflow execution. It also uses this to synchronize efforts between the multiple servers.
- Pub-Sub Mechanism: Sliderule delays persistence by instead writing results of an execution to a pub sub mechanism, thus avoiding a costly database write during execution.
- Document Store: Sliderule has several functionalities that rely on digesting files, so it needs a place to put them.
- Encryption/Key Manager: Sliderule does not manage its own encryption, but instead relies on cloud services to do so.
- Data Lake: Sliderule generates a lot of data over time, and needs to periodically move this data out of its primary data store to a more long term scalable storage.
Architecture Diagrams
ECS Diagram
EKS Diagram
Updated 3 months ago